

Redis 学习笔记
Redis 为什么选择单线程
什么是 Redis 的单线程
- Redis 单线程主要是指 Redis 的网络 IO 和键值对读写是由一个线程来完成的,Redis 在处理客户端的请求时包括获取 socket 读、解析、执行、内容返回 socket 写等都由一个顺序串行的主线程处理,这就是所谓的“单线程”,这也是 Redis 对外提供键值存储服务的主要流程,但 Redis 的其他功能,比如持久化、异步删除、集群数据同步等是由额外的线程执行的
- Redis的版本很多3.x、4.x、6.x,版本不同架构也是不同的,不限定版本问是否单线程也不太严谨
- 3.x版本是单线程,4.x版本,负责处理客户端请求的线程是单线程,异步删除是多线程
- 在 Redis 6.0 中新增了多线程的功能来提高 I/O 的读写性能,他的主要实现思路是将主线程的 IO 读写任务拆分给一组独立的线程去执行,这样就可以使多个 socket 的读写可以并行化了,采用多路 I/O 复用技术可以让单个线程高效的处理多个连接请求,尽量减少网络IO的时间消耗,将最耗时的Socket的读取、请求解析、写入独立出去,剩下的命令执行仍然由主线程串行执行并和内存的数据交互
Redis3.x单线程时代但性能依旧很快的原因
- 基于内存操作:Redis 的所有数据都存在内存中,因此所有的运算都是内存级别的,所以他的性能比较高
- 数据结构简单:Redis 的数据结构是专门设计的,而这些简单的数据结构的查找和操作的时间大部分复杂度都是 O(1),因此性能比较高
- 多路复用和非阻塞 I/O:Redis使用 I/O多路复用功能来监听多个 socket连接客户端,这样就可以使用一个线程连接来处理多个请求,减少线程切换带来的开销,同时也避免了 I/O 阻塞操作
- 避免上下文切换:因为是单线程模型,因此就避免了不必要的上下文切换和多线程竞争,这就省去了多线程切换带来的时间和性能上的消耗,而且单线程不会导致死锁问题的发生
既然单线程这么好,为什么逐渐又加入了多线程特性
- 正常情况下使用 del 指令可以很快的删除数据,而当被删除的 key 是一个非常大的对象时,例如时包含了成千上万个元素的 hash 集合时,那么 del 指令就会造成 Redis 主线程卡顿
- 在Redis 4.0就引入了多个线程来实现数据的异步惰性删除等功能,但是其处理读写请求的仍然只有一个线程,所以仍然算是狭义上的单线程
Redis6 的多线程和IO多路复用入门
对于Redis主要的性能瓶颈是内存或者网络带宽而并非 CPU
如何开启多线程
- 在Redis6.0中,多线程机制默认是关闭的,如果需要使用多线程功能,需要在redis.conf中完成两个设置
- 设置
io-thread-do-reads配置项为yes,表示启动多线程 - 设置线程个数。关于线程数的设置,官方的建议是如果为 4 核的 CPU,建议线程数设置为 2 或 3,如果为 8 核 CPU 建议线程数设置为 6,线程数一定要小于机器核数,线程数并不是越大越好
Redis 数据类型
http://doc.redisfans.com/index.html
String
最常用
- set key value
- get key
设置 / 获取多个值
- mset key value [key value ...]
- mget key [key ...]
数值增减
- 递增:incr key
- 递增指定的整数: incrby key increment
- 递减数字:decr key
- 减少指定的整数:decrby key decrement
- 获取字符串长度:strlen key
分布式锁
- setnx key value
应用场景
- 抖音点赞
- 是否喜欢的文章
Hash
- Map<String, Map<object,object>>
- 一次设置一个字段值:hset key field value
- 一次获取一个字段值:hget key field
- 一次设置多个字段值:hmset key field value [field value ...]
- 一次获取多个字段值:hmget key field [field ...]
- 获取所有字段值:hgetall key
- 获取某个 key 内的全部数量:hlen key
- 删除一个 key:hdel key
应用场景
- 购物车
- 新增商品:hset shopcar:uid1024 334488 1
- 增加商品数量:hincrby shopcar:uid1024 334488 1
- 减少商品数量:hincrby shopcar:uid1024 334488 -1
- 商品总数:hlen shopcar:uid1024
- 全部选择:hgetall shopcar:uid1024
List
应用场景
- 微信公众号订阅消息
- 商品评论列表
Set
-
微信抽奖小程序
- 立即参与:sadd key uid
- 显示抽奖人数:scard key
- 抽奖
- srandmember key 2:随机抽奖2个人,元素不删除
- spop key 3:随机抽奖3个人,元素删除
-
微信朋友圈点赞
- 新增点赞:sadd pub:msgid uid
- 取消点赞:srem pub:msgid uid
- 展现所有点赞用户:smembers pub:msgid
- 点赞统计:scard pub:msgid
- 判断某个朋友是否对楼主点赞:sismember pub:msgid uid
-
微博社交关系
- 共同关注:sinter s1 s2
- 我关注的人也关注他:两次 sismember 就可以了
-
可能认识的人
sdiff a b:在a集合中而不在b集合中的sdiff b a:在b集合中而不在a集合中的sinter a b:a、b集合公用的
SortedSet
应用场景
根据商品销售对商品进行排序显示
- 商品编号 1001 销量为 9,商品编号 1002 销量为 15
- zadd goods:sellsort 9 1001 15 1002
- 有一个客户又买了 2 件商品 1001,商品编号 1001 销量加 2
- zincrby goods:sellsort 2 1001
- 求商品销量前10
- zrevrange goods:sellsort 0 9 withscores
抖音热搜
- 点击视频
- zincrby hotvcr:20200919 1 八佰
- zincrby hotvcr:20200919 15 八佰 2 花木兰
- 展示当日排行前10
- zrevrange hotvcr:20200919 0 9 withscores
Bitmap
用 String 类型作为底层数据结构实现的一种统计二值状态的数据类型,位图本质是数组,它是基于String数据类型的按位的操作,该数组由多个二进制位组成,每个二进制位都对应一个偏移量,我们可以称之为个索引或者位格
Bitmap支持的最大位数是2的32次方,它可以极大的节约存储空间,使用 512M 内存就可以存储最大42.9亿字节信息
应用场景
-
签到
-
getbit
-
setbit
-
strlen
-
bitcount
-
bitop
HyperLogLog
去重统计的基数估计算法
在 Redis 中,每个 HyperLogLog 键只需要花费 12KB 内存就可以计算接近 2 的64次方个不同元素的基数
- 将所有元素添加到 key 中:pfadd key element ...
- 统计key的估算值:pfcount key
- 合并 key 到新 key:pgmerge new_key key1 key2 ...
应用场景
- UV、PV、DAU、MAU
GEO
http://redis.cn/commands/geoadd.html
应用场景
- 地理位置
Stream
为什么 Redis 集群的最大槽数是 16384 个
Redis 集群并没有使用一致性 hash 而是引入了哈希槽的概念,Redis 集群有16384个哈希糟,每个 key 通过 CRC16 校验后对 16384 取模来决定放置哪个槽,集群的每个节点负责一部分 hash 槽,但为什么哈希槽的数量是16384,2的14次方呢
CRC16算法产生的 hash 值有 16bit,该算法可以产生 2^16=65536 个值,换句话说值是分布在 0~65535 之间,那作者在做 mod 运算的时候,为什么不 mod65536,而选择mod6384?
如果槽位为65536,发送心跳信息的消息头达8k,发送的心跳包过于庞大
在消息头中最占空问的是 myslots[CLUSTER_SLOTS/8],当槽位 为 655361 时,这块的大小是:65536/8/1024=8kb,因为每秒钟,Redis 节点需要发送一定数量的 ping 消息作为心跳包,如果档位为 65536,这个 ping 消息的消息头太大了,浪费带宽
Redis 的集群主节点数最基本不可能超过1000个,集群节点越多,心跳包的消息体内携带的数据就越多,如果节点过 1000 个,也会导致网络拥堵,因此 redis 作者不建议 redis cluster 节点数量超过1000个,那么,对于节点数在 1000 以内的 redis cluster 集群,16384个槽位够用了,没有必要拓展到 65536 个
槽位越小,节点少的情况下,压缩比高,容易传输,Redis 主节点的配置信息中它所负责的哈希槽是通过一张 bitmap 的形式保存的,在传输过程中会对 bitmap 进行压缩,但是如果 bitmap 的填充率 slots/n 很高的话 (n表示节点数),bitmap的压缩率就很低,如果节点数很少,而哈希槽数很多的话,bitmap的压缩率也低
布隆过滤器
特点
- 高效地插入和查询,占用空间少,返回的结果是不确定性的
- 一个元素如果判断结果为存在的时候元素不一定存在,但是判断结果为不存在的时候则一定不存在
- 布隆过滤器可以添加元素,但是不能删除元素,因为删掉元素会导致误判率增加
- 误判只会发生在过滤器没有添加过的无素,对于添加过的元素不会发生误判
实现原理
初始化
布隆过滤器本质上是由长度为 m 的位向量或位列表(仅包含 0 或 1位值的列表)组成,最初所有的值均设置为 0
添加
当我们向布隆过滤器中添加数据时,为了尽量地址不冲突,会使用多个 hash 函数对 key 进行运算,算得一个下标索引值,然后对位数组
长度进行取模运算得到一个位置,每个 hash 函数都会算得一个不同的位置,再把位数组的这几个位置都置为 1 就完成了 add 操作
判断
向布隆过滤器查询某个 key 是否存在时,先把这个key 通过相同的多个hash 两数进行运算,查看对应的位置是否都为 1,只要有一个位为 0,那么说明布隆过滤器中这个 key 不存在
如果这几个位置全都是 1,那么说明极有可能存在,因为这些位置的 1 可能是因为其他的 key 存在导致的,也就是前面说过的 hash冲突
总结
使用时 最好不要让实际元素数量远大于初始化数量
当实际元素数量超过初始化数量时,应这对布隆过滤器进行重建,重新分配 size 更大的过滤器,再将所有的历史元素批量 add 进去
优点:高效的插入和查询,占用空间少
缺点:不能删除元素,存在误判
使用场景
缓存穿透
黑名单校验
白名单过滤
布谷鸟过滤器
Redis 数据统计
统计类型
-
聚合统计
- 统计多个集合元素得聚合结果,交并差集
-
排序统计
-
list
-
zset
-
-
二值统计
- 集合元素的取值就只有 0 和 1 两种
- 签到
- bitmap
-
基数统计
- 统计一个集合中不重复的元素个数
- hyperloglog
缓存雪崩
- redis 集群宕机
- redis 大量 key 失效
解决方案
- 本地缓存 + Hystrix + sentinel 限流
- aof / rdb 备份及时恢复
缓存穿透
- 记录不存在,每次都穿过 redis 到底层 db
解决方案
- 空对象缓存或者默认值
- 布隆过滤器:guava、redis、redisbloom 插件
缓存击穿
热点 key 失效,大量请求到 MySQL
解放方案
- 互斥更新,随机退避,差异失效时间
- 热点 key 不设置时间
- 互斥独占锁防止击穿(双端检索:redis 未查到数据,进行加锁,加锁之后再次查询 redis 是否存在缓存,如果还没有,就去查数据库,防止加锁期间 redis 已经有数据了)
- 设置多级缓存
- 新建:开辟两块缓存,主 A 从 B,先更新缓存 B 再更新缓存 A
- 查询:先查询主缓存 A,如果 A 没有再查询 B
- A 设置的缓存时间比 B 的时间短
- A 失效需要检测线程去重新设置缓存
Redis 分布式锁
特点
- 独占性
- 任何时刻只能有且仅有一个线程持有
- 高可用
- 在集群环境下,不能因为某一个节点挂了而出现获取锁失败的情况
- 防死锁
- 杜绝死锁,必须有超时控制或者撤销操作
- 不乱抢
- 只能自己加锁,自己释放
- A、B 同时抢锁,A 抢到了锁,默认过期时间为 30s,A 开始执行业务逻辑,B 等待,A 占用锁超过了 30s 自动释放了锁,但是 A 的业务还在执行,B 看到锁被释放,就抢到了锁,此时 A 业务执行完毕,开始手动删除锁,但是这个时候删除的就是 B 持有的锁
- 删除锁的时候也必须使用 LUA 脚本保证原子性
- 只能自己加锁,自己释放
- 可重入
- 同一个线程可多次获得锁在未释放锁之前
Redlock
基于 SETNX 分布式锁的缺点
- 客户 A 通过 Reais 的 setnx 命令建分布式锁成功并持有锁
- 正常情况主从机都有这个分布式锁
- Master 出故障了,Master 还没来得同步数据给 Slave,此时 slave 机器上没有对应锁的信息
- 从机 slave 上位,变成了新 Master
- 客户 B 照样可以同样的建锁成功,出现了可怕情况:—锁被多建多用,CAP里面的 CP 遭到了破坏,哨兵和主从均有这样的风险
容错率公式
N(集群数量)= 2 * X(宕机数量)+ 1
设计理念
该方案也是基于 setnx 加锁、lua 脚本解锁进行改良的,大致方案如下
假设我们有 N 个 Redis 主节点,例如 N=5,这些节点是完全独立的,我们不使用复制或任何其他隐式协调系统
为了取到锁客户端执行以下操作
- 获取当前时间,以毫秒为单位
- 依次尝试从 5 个实例,使用相同的 key 和随机值,例如 UUID 获取锁,当向 Redis 请求获取锁时,客户端应该设置一个超时间,这个超时时间应该小于锁的失效时间,例如你的锁自动失效时间为10 秒,则超时时间应该在 5-50 毫秒之间,这样可以防止客户端在试图与一个宕机的 Redis 节点对话时长时间处于阻塞状态,如果一个实例不可用,客户端应该尽快尝试去另外Redis 实例请求获取锁
- 客户端通过当前时间减去步骤 1 记录的时间来计算获取锁使用的时间,当且仅当从大多数 (N / 2 + 1,这里是 3 个节点) 的Redis 节点都取到锁,并且获取锁使用的时间小于锁失效时间时,锁才算获取成功
- 如果取到了锁,其真正有效时问等于初始有效时间减去获取锁所使用的时间:步骤3计算的结果
- 如果由于某些原因未能获得锁,比如无法在至少 N/2+1个 Redis 实例获取锁、或获取锁的时间超过了有效时间,客户端应该在所有的 Redis 实例上进行解锁,即便某些 Redis 实例根本就没有加锁成功,防止某些节点获取到锁但是客户端没有得到响应而致接下来的一段时间不能被重新获取锁
该方案为了解决数据不一致的问题,直按舍弃了异步复制只使用 master 节点,同时由于舍弃了slave,为了保证可用性,引入了N个节点,官方建议是5
客户端只有在满足以下2个条件才被认为加锁成功
- 客户端从超过半数的 Redis 实例上获取到了锁
- 客户端获取锁的时间没有超过锁的有效时间
加锁机制
- 通过 exists 判断,如果锁不存在,则设置值和过期时间,加锁成功
- 通过 hexists 判断,如果锁已存在,并且锁的是当前线程,则证明是重入锁,加锁成功
- 如果锁已经存在,但是锁的不是当前线程,则证明是有其他的线程持有锁,返回当前锁的过期时间,加锁失败
- 具体加锁
- 加锁成功后,会在 redis 的内存结构中,放一条 hash 结构的数据,key 为锁的名称,field 为随机字符串 + 线程 ID,值为1
- 如果同一线程多次调用 lock 方法,值递增 1,即实现了可重入
watch dog 自动续期机制
客户端 A 加锁成功,就会启动一个 watch dog 看门狗,它是一个后台线程,会每隔10秒检查一下,如果客户端 A 还持有锁 key,那么就会不断的延长锁 key 的生存时间,默认每次续命又从30秒新开始
Redis 删除策略
立即删除
惰性删除
定期删除
Redis 缓存淘汰策略
- noeviction:返回错误,不会删除任何键值
- allkeys-lru:使用 LRU 算法删除最近最少使用的键值
- volatile-lru:使用 LRU 算法从设置了过期时间的键集合中删除最近最少使用的键值
- allkeys-random:从所有 key 随机删除
- volatile-random:从设置了过期时间的键的集合中随机删除
- volatile-ttl:从设置了过期时间的键中删除剩余时间最短的键
- volatile-lfu:从配置了过期时间的键中删除使用频率最少的键
- allkeys-lfu:从所有键中删除使用频率最少的键
Redis 默认第一个策略,推荐:allkeys-lru
Redis 源码结构
基本数据结构
- 简单动态字符串:sds.c
- 整数集合:intset.c
- 压缩列表:ziplist.c
- 快速链表:quicklist.c
- 字典:dict.c
- Streams 底层结构:listpack.c、rax.c
数据类型底层实现
- Redis 对象:object.c
- 字符串:t_string.c
- 列表:t_list.c
- 字典:t_hash.c
- 集合和有序集合:t_set.c、t_zset,c
- 数据流:t_stream.c
数据库实现
- db.c
- rdb.c
- aof.c
服务端与客户端实现
- 事件驱动:ae.c、ae_epoll.c
- 网络连接:anet.c、networking.c
- 服务端程序:server.c
- 客户端程序:redis-cli.c
其他
- 主从复制:replication.c
- 哨兵:sentinel.c
- 集群:cluster.c
- hyperloglog.c、geo.c
KV 究竟是什么
- Redis 是 key-value 存储系统,每个键值对都会有一个 dictEntry,其中 key 一般是字符串,value 类型则是 redis 对象:redisObject
- Bitmap、Hyperloglog 底层是 String,GEO 底层是 Zset
RedisObject 结构
typedef struct redisObject {
// 刚刚好32 bits
// 对象的类型,字符串/列表/集合/哈希表
unsigned type:4;
// 未使用的两个位
unsigned notused:2; /* Not used */
// 编码的方式,(int、embstr、raw)Redis 为了节省空间,提供多种方式来保存一个数据
// 譬如:“123456789” 会被存储为整数123456789
unsigned encoding:4;
// 上次访问的时间戳,当内存紧张,淘汰数据的时候用到
unsigned lru:22; /* lru time (relative to server.lruclock) */
// 引用计数, 用于垃圾回收
int refcount;
// 数据指针,指向对象实际的数据结构
void *ptr;
} robj;
String 数据结构介绍
SDS
Redis 没有直接复用 C 语言的字符串,而是新建了属于自己的结构 SDS,在 Redis 数据库里,包含字符串值的键值对都是由 SDS 实现的Redis中所有的键都是由字符串对象实现的即底层是由SDS实现,Redis中所有的值对象中包含的字符串对象底层也是由SDS实现
SDS 结构
- 一个字符串最大为 512 MB
- len:已用的字节长度
- alloc:字符串最大字节长度
- flags:用来表示 sds 类型
- buf[]:真正有效的字符串数据,长度由 alloc 控制
SDS 有多种结构
- sdshdr5:2 ^ 5 = 32 byte
- sdshdr8:2 ^ 8 = 256 byte
- sdshdr16:2 ^ 16 = 65536 byte = 64KB
- sdshdr32:2 ^ 32 byte = 4GB
- sdshdr64:2 ^ 64 byte =17179869184G
- len 表示 SDS 的长度,使我们在获取字符串长度的时候可以在 O(1) 情况下拿到,而不是像 C 那样需要遍历一遍字符串
- alloc 可以用来计算 free 就是字符串己经分配的未使用的空问,有了这个值就可以引入预分配空间的算法了,而不用去考虑内存分配的问题
- buf 表示字符串数组真实数据的
为什么要重新设计一个 SDS 数据结构
字符串长度处理
- C 语言需要从头开始遍历,直到遇到
\0为止,时间复杂度 O(N) - SDS 记录当前字符串长度,直接读取就可以了,时间复杂度 O(1)
内存重新分配
- C 语言分配内存空间超过后,会导致数组下标越界或者内存分配溢出
- SDS
- 空间预分配:SDS 修改后,len 长度小于 1M,那么将会额外分配与 len 相同长度的未使用空间,如果修改后长度大于 1M,那么将分配 1M 的使用空间
- 惰性空间释放:有空间分配对应的就有空间释放,SDS 缩短时并不会回收多余的内存空间,而是使用 free 字段将多出来的空间记录下来,如果后续有变更操作,直接使用free 中记录的空间,减少了内存的分配
二进制安全
- 二进制数据并不是规则的字符串格式,可能会包含一些特殊的字符,比如
\0 - 前面提到过,C 中字符串遇到
\0会结束, 而 SDS 根据 len 长度来判断字符串结束的,不存在二进制的安全问题
编码格式
- int
- 保存 long 型的64位有符号整数
- 只有整数才会使用int,如果是浮点数,Redis 内部先将浮点数转化为字符串值,然后再保存
- Redis 启动时会预先建立10000 个分别存储 0~9999 的 redisObject 变量作为共享对象,这就意味着如果 set 字符串的键值在 0~10000 之间的话,则可以直接指向共享对象而不需要再建立新对象,此时健值不占空问
- embstr
- 代表 embstr 格式的 SDS (simple dynamic string) 简单动态字符串,保存长度小于44字节的字符串
- EMBSTR:表示嵌入式的 String
- 对于长度小于 44 字节的字符串,Redis 对键值采用 OBJ_ENCODING_EMBSTR 方式,EMBSTR 顾名思义即:embedded string,表示嵌入式 String,从内存结构上来讲,即字符串 sds 结构体与其对应的 redisObject 对象分配在同块连续的内存空间,像字符串 sds 嵌入在 redisObiect 对象之中一样
- 对于 embstr,由于其实现是只读的,因此在对 embstr 对象进行修改时,都会先转化为 raw 再进行修改,因此,只要是修改embstr 对象,修改后的对象一定是 raw 的,无论是否达到了 44 个字节
- raw
- 保存长度大于 44 字节的字符串
- 当字符串的键值为长度大于 44 字节的超长字符串时,Redis 则会将键值的内部编码方式改为 OBJ_ENCODING_RAW 格式,这与
OBJ_ENCODING_EMBSTR 编码方式的不同之处在于,此时动态字符串 sds 的内存与其依赖的 redisObject 的内存不再连续
总结
| 类型 | 备注 |
|---|---|
| int | Long 类型整数时,RedisObject中的 ptr 指针直接赋值为整数数据,不再额外的指针再指向整数了,节省了指针的空间开销 |
| embstr | 当保存的是字符串数据且字符串小于等于 44 字节时,embstr 类型将会调用内存分配函数,只分配一块连续的内存空间,空间中依次包含 redisObject 与 sdshdr 两个数据结构,让元数据、指针和 SDS 是一块连续的内存区城,这样就可以避免内存碎片 |
| raw | 当字符串大于 44 字节时,SDS 的数据变多变大了,SDS 和 RedisObject 布局分家各自过,会给 SDS 分配多的空间并用指针指向 SDS 结构,raw 类型将会调用两次内存分配函数,分配两块内存空间,一块用于包含 redisObjiect 结构,而另一块用于包含 sdshdr 结构 |
Hash 数据结构介绍
Ziplist
ziplist 压缩列表是一种紧凑编码格式,总体思想是多花时问来换取节约空间,即以部分读写性能为代价,来换取极高的内存空间利用率,因此只会用于字段个数少,且字段值也较小的场景,压缩列表内存利用率极高的原因与其连续内存的特性是分不开的
想想我们的学过的一种 GC 垃圾回收机制:标记 - 压缩算法,当一个 hash 对象只包含少量键值对且每个键值对的健和值要么就是小整数要么就是长度比较短的字符串,那么它用 ziplist 作为底层实现
ziplist是一个经过特殊编码的双向链表,它不存储指向上一个链表节点和指向下一个链表节点的指针,而是存储上一个节点长度和当前节点长度,通过栖牲部分读写性能,来换取高效的内存空问利用率,节约内存,是一种时问换空间的思想,只用在字段个数少,字段值小的场景里面
压缩列表节点构成

压缩列表是 Redis 为节约空问而实现的一系列特殊编码的连线内存块组成的顺序型数据结构,本质上是字节数组,在模型上将这些连续的数组分为 3 大部分,分別是 header + tentry 集合 + end,其中 header 是由 zlbytes + zltail + zllen 组成,entry 是节点,zlend 是一个单字节 255,用作 ZipList 的结尾标识符
| 属性 | 类型 | 长度 | 用途 |
|---|---|---|---|
| zlbytes | uint_32t | 4B | 记录整个压缩列表占用的内存字节数:在对压缩列表进行内存重分配或者计算 zlend 的位置时使用 |
| zltail | uint_32t | 4B | 记录压缩列表表尾节点距离压缩列表的起始地址有多少字节:通过这个偏移量,程序无须遍历整个压缩列表就可以确定表尾节点的地址 |
| zllen | uint_16t | 2B | 记录了压缩列表包含的节点数量: 当这个属性的值小于UINT16_ MAX (65535)时, 这个属性的值就是压缩列表包含节点的数量,当这个值等于 UINT16_MAX 时, 节点的真实数量需要遍历整个压缩列表才能计算得出 |
| entryX | 列表节点 | 不定 | 压缩列表包含的各个节点,节点的长度由节点保存的内容决定 |
| zlend | uint_8t | 1B | 特殊值 0xFF (十进制 255 ),用于标记压缩列表的末端 |
zlentry 节点结构
/* 在内存中并没有存下下面结构体zlentry的内容,只是为了方便,在代码中定义了这样的结构体,包含了一些其他信息
*/
typedef struct zlentry {
// 上一个链表节点占用的长度
unsigned int prevrawlensize;
// 存储上一个链表节点的长度数值所需要的字节数
unsigned int prevrawlen;
// 存储当前链表节点的长度数值所需要的字节数
unsigned int lensize;
// 当前链表节点占用的长度
unsigned int len;
// 当前链表节点的头部大小
unsigned int headersize;
// 编码方式
unsigned char encoding;
// 压缩链表以字符串的形式保存,该指针指向当前节点起始位置
unsigned char *p;
} zlentry;
明明有链表了,为什么出来一个压缩链表?
- 普通的双向链表会有两个指针,在存储数据很小的情况下,我们存储的实际数据的大小可能还没有指针占用的内存大,得不偿失,ziplist 是一个特殊的双向链表,没有维护双向指针:prev next,而是存储上一个 entry 的长度和当前 entry 的长度,通过长度推算下一个元素在什么地方,牺牲读取的性能,获得高效的存储空间,因为 (简短字符串的情况) 存储指针比存储 entry 长度更费内存,这是典型的 “时间换空间”
- 链表在内存中一般是不连续的,遍历相对比较慢,而 ziplist 可以很好的解决这个问题,普通数组的通历是根据数组里存储的数据类型找到下个元素的 (例如 int 类型的数组访问下一个元素时每次只需要移动一个 sizeof(int) 就行),但是 ziplist 的每个节点的长度是可以不一的,而我们面对不同长度的节点又不可能直接 sizeof(entry),所以 ziplist 只好将一些必要的偏移量信息记录在了每一个节点里,使之能跳到上一个节点或下一个节点
- 头节点里有头花点里同时还有一个参数 len,和 string 类型的 SDS 类似,这里是用来记录链表长度的,因此获取链表长度时不用再遍历整个链表,直接拿到 len 值就可以了,这个时间复杂度是 O(1)
压缩列表的通历
通过指向表尾节点的位置指针 p1,减去节点的 previous_entry_llength,得到前一个节点起始地址的指针,如此循环,从表尾遍历到表头节点,从表尾向表头遍历操作就是使用这一原理实现的,只要我们拥有了一个指向某个节点起始地址的指针,那么通过这个指针以及这个节点的 previous_entry_length 属性,程序就可以一直向前一个节点回溯,最终到达压缩列表的表头节点
HashTable
-
hash-max-ziplist-entries
- 使用压缩列表保存时哈希集合中的最大元素个数
- 默认哈希对象保存的键值对数量不超过为 512个
-
hash-max-ziplist-value
- 使用压缩列表保存时哈希集合中单个元素的最大长度
- 默认所有的键值对的健和值的字符串长度不超过 64 byte
-
Hash 类型键的字段个数小于 hash-max-ziplist-entries 并且每个字段名和字段值的长度小于 hash-max-zjplistvalue 时,Redis 才会使用 OBJ_ENCODING_ZIPLIST 来存储该键,前述条件任意一个不满足则会转换为 OBJ_ENCODING_HT 的编码方式
-
ziplist 升级到 hashtable 之后就无法再降级到 ziplist
-
hashtable 是由数组加链表构成
List 数据结构介绍
- List 用 quicklist 来存储,quicklist 存储了一个双向链表,每个节点都是一个 ziplist
- 在低版木的 Redis 中,list 采用的底层数据结构是 ziplist + linkedList
- 高版本的 Redis 中底层数据结构是 quicklist,它替换了 ziplist + linkedList,而 quicklist 也用到了ziplist
- quicklist 实际上是 zipList 和 linkedList 的混合体,它将 linkedList 按段切分,每一段使用zipList 来紧凑存储,多个 ziplist 之间使用双向指针串接起来
list-compress-depth 0
表示一个 quickist 两端不被压缩的节点个数,这里的节点是指 quickist 双向链表的节点,而不是指 ziplist 里面的数据项个数
参数 list-compress-depth 的取值含义如下
- 0:是个特殊值,表示都不压缩,这是 Redis 的默认值
- 1:表示 quicklist 两端各有 1 个节点不压缩,中向的节点压缩
- 2:表示 quickist 两端各有 2 个节点不压缩,中问的节点压缩
- 3:表示 quicklist 两端各有 3 个节点不压缩,中间的节点压缩
list-max-ziplist-size -2
当取正值的时候,表示按照数据项个数来限定每个 quicklist 节点上的 ziplist 长度。比如,当这个参数配置成 5 的时候,表示每个quicklist 节点的 ziplist 最多包含 5 个数据项,当取负值的时候,表示按照占用字节数来限定每个 quicklist 节点上的 ziplist 长度,这时它只能取 -1 到 -5 这五个值
- -5: 每个quicklist节点上的ziplist大小不能超过64 Kb
- -4: 每个quicklist节点上的ziplist大小不能超过32 Kb
- -3: 每个quicklist节点上的ziplist大小不能超过16 Kb
- -2: 每个quicklist节点上的ziplist大小不能超过8 Kb
(默认值) - -1: 每个quicklist节点上的ziplist大小不能超过4 Kb
quicklist 结构体
typedef struct quicklist{
//指向双向链表的表头
quicklistNode *head;
//指向双向链表的表尾
quicklistNode *tail;
// 所有的ziplist存储的元素数量
unsigned long count
// 双向链表的长度,node的数量
unsigned long len
int fill : 16
// 压缩深度,1代表不压缩
unsigned int compress : 16
} quicklist
Set 数据结构介绍
- 当集合中的元素都是整数且元素个数小于 set-maxintset-entries 配置(默认512个)时,Redis 会选用 intset 来作为集合的内部实现,从而减少内存的使用
- 当集合类型无法满足 intset 的条件时,Redis 会使用 hashtable (数组 + 链表) 作为集合的内部实现,key 就是元素的值,value 为 null
ZSet 数据结构介绍
当有序集合中包含的元素数量超过服务器属性 server.zset_ max_ziplist_entries 的值,默认值为 128,或者有序集合中新添加元素的 member 的长度大于服务器属性 server.zset_max_ziplist_value 的值,默认值为 64 时,Redis 会使用跳跃表作为有序集合的底层实现,否则会使用 ziplist 作为有序集合的底层实现
总结
字符串
- int:8个字节的长整型
- embst:小于等于 44 个字节的字符串
- raw:大于44个字节的宇符串
- Redis 会根据当前值的类型和长度决定使用哪种内部编码实现
哈希
- ziplist(压缩列表):当哈希类型元素个数小于 hash_max_ziplist_entries 配置,默认是 512 个,同时所有值都小于 hash_max_ziplist_valve 配置(默认64字节)时,Redis 会使用 ziplist 作为哈希的内部实现,ziplist 使用更加紧凑的结构实现多个元素的连续存储,所以在节省内存方面比 hashtable 更加优秀
- hashtable (哈希表):当哈希类型无法满足 ziplist的条件时,Redis 会使用 hashtable 作为哈希的内部实现,因为此时 ziplist 的读写效率会下降,而 hashtable 的读写时间复杂度为 O(1)
列表
- ziplist (压缩列表):当列表的元素个数小于 list_max_ziplist_entries 配置(默认512个),同时列表中每个元素的值都小于 list_max_ziplist_valve 配置时,默认64字节,Redis 会选用 ziplisy 来作为列表的内部实现来减少内存的使用
- linkedlist (链表):当无法满足 ziplist 的条件时,Redis 会使用 linkedlist 作为列表的内部实现,quickiist、ziplist 和 linkedlist 的结合以zplist 为节点的链表 (linkedlist)
集合
- intset (整数集合):当集合中的元素都是整数且元素个数小于 set_max_intset_entries 配置(默认512个)时,Redis 会选用 intset 来作为集合的内部实现,从而减少内存的使用
- hashtable (哈希表):当集合类型无法满足 intset 的条件时,Redis 会使用 hashtable 作为集合的内部实现
有序集合
zipist压缩列表):当有序集合的元素个数小于 zset_max_ziplist_enties 配置 (默认128个),同时每个元素的值都小于 zset_max_ziplist_valve 配置(默认64字节时),Redis 会用 ziplist 来作为有序集合的内部实现,ziplist 可以有效减少内存的使用
skiplist (跳跃表):当 ziplist 条件不满足时,有序集合会使用 skiplist 作为内部实现,因为此时ziplist 的读写效率会下降
时间复杂度
| 名称 | 时间复杂度 |
|---|---|
| 哈希表 | O(1) |
| 跳表 | O(logN) |
| 双向链表 | O(N) |
| 压缩列表 | O(N) |
| 整数数组 | O(N) |
跳表
- 链表 + 多级索引
- 时间复杂度:O(logN)
- 空间复杂度:O(n)
Canal
MySQL 的主从复制原理
- 当 master 主服务器上的数据发生改变时,则将其改变写入二进制事件日志文件中
- salve 从服务器会在一定时间间隔内对 master 主服务器上的二进制日志进行探测,探测其是否发生过改变,如果探测到 master 主服务器的二进制事件日志发生了改变,则开始一个 I/O Thread 请求 master 二进制事件日志
- 同时 master 主服务器为每个 I/O Thread 启动一个 dump Thread,用于向其发送二进制事件日志
- slave 从服务器将接收到的二进制事件日志保存至自己本地的中继日志文件中
- salve 从服务器将启动 SQL Thread 从中继日志中读取二进制日志,在本地重放,使得其数据和主服务器保持一致
- 最后 I/O Thread 和 SQL Thread 将进入睡眠状态,等待下一次被唤醒
Canal 工作原理
- canal 模拟 MySQL Slave 的交互协议,伪装自己为 MySQL slave,向 MySQL master 发送 dump 协议
- MySQL master 收到 dump 请求,开始推送 binary log 给 slave (即 canal)
- canal 解析 binary log 对象 (原始为 byte 流)
https://github.com/alibaba/canal/wiki/QuickStart
缓存双写一致性探讨
- 如果 Redis 中有数据,需要和数据库中的值相同
- 如果 Redis 中无数据,数据库的值需要是最新值
缓存操作类型
- 只读缓存
- 读写缓存
- 对于直写策略:写缓存时也同步写数据库,缓存和数据库的数据一致
- 对于读写缓存来说,要想保证缓存和数据库的数据一致,就要采用同步直写策略
缓存更新策略
-
先更新数据库,再更新缓存
-
先删除缓存,再更新数据库
-
过程
- 线程 A 进行写操作,删除缓存后,A 还未完成更新
- 线程 B 查询,查询 redis 发现缓存不存在
- 线程 B 继续,去数据库查询得到了 mysql 中的旧值
- 线程 B 将旧值写入 redis 缓存
- 线程 A 将新值写入 mysql 数据库
- 上述情况就会导致线程 B 读到了 mysql 中的旧值
-
解决方案
- 延时双删:先删除缓存,再更新数据库,休眠一段时间,再删除一遍缓存
-
双删产生的问题
- 删除的休眠时间
- mysql 主从读写分离架构:适当增加休眠时间
- 吞吐量:异步启动线程去删除
-
-
旁路缓存模式:先更新数据库,再删除缓存
- 问题:写线程可能还没完成删除缓存的操作,读线程会读取到 redis 旧值
- 解决方案(canal)
- 更新数据库数据
- 数据库会将操作信息写入 binlog 日志当中
- 订阅程序提取出所需要的数据以及 key
- 另起一段非业务代码,获得该信息
- 尝试删除缓存操作,发现删除失败
- 将这些信息发送至消息队列
- 重新从消息队列中获得该数据,重试操作
总结
在大多数业务场景下,我们会把 Redis 作为只读级存使用,假如定位是只读缓存来说,理论上我们既可以先删除缓存值再更新数据库,也可以先更新数据库再删除缓存,但是没有完美方案,两害趋其轻的原则
个人建议是,优先使用先更新数据库,再删除缓存的方案,理由如下
- 先删除缓存值再更新数据库,有可能导致请求因缓存失效而访问数据库,给数据库带来压力,严重号致打满 mysql
- 如果业务应用中读取数据库和写缓存的时问不好估算,那么,延迟双删中的等待时间就不好设置
如果使用先更新数据库,再删除的方案
如果业务层要求必须读取一致性的数据,那么我们就需要在更新数据库时,先在 Redis 缓存客户端暂存并发读请求,等数据库更新完,缓存值删除后,再读取数据,从而保证数据一致性
抢红包业务
发红包数据结构
- list
抢红包算法-二倍均值法
假设剩余红包金额为 M,剩余人数为 N,那么有如下公式
每次抢到的金额为:(0,(M/N)*2))
存红包
- hash
短链接业务
短链接算法
- 新浪短链接算法
短链接存储
- 用 hash 存储,field 为业务字段,key 为短链接的加密串,value 为原始 url
IO 多路复用
Redis 的 IO 多路复用
- I/O:网络 IO
- 多路:多个客户端连接,连接就是套接字描述符,即 socket 或者 channel
- 复用:复用一个或几个线程,也就是说一个或一组线程处理多个 TCP 连接,使用单进程就能够实现同时处理多个客户端的连接,其发展可以分为:select -> poll -> epoll
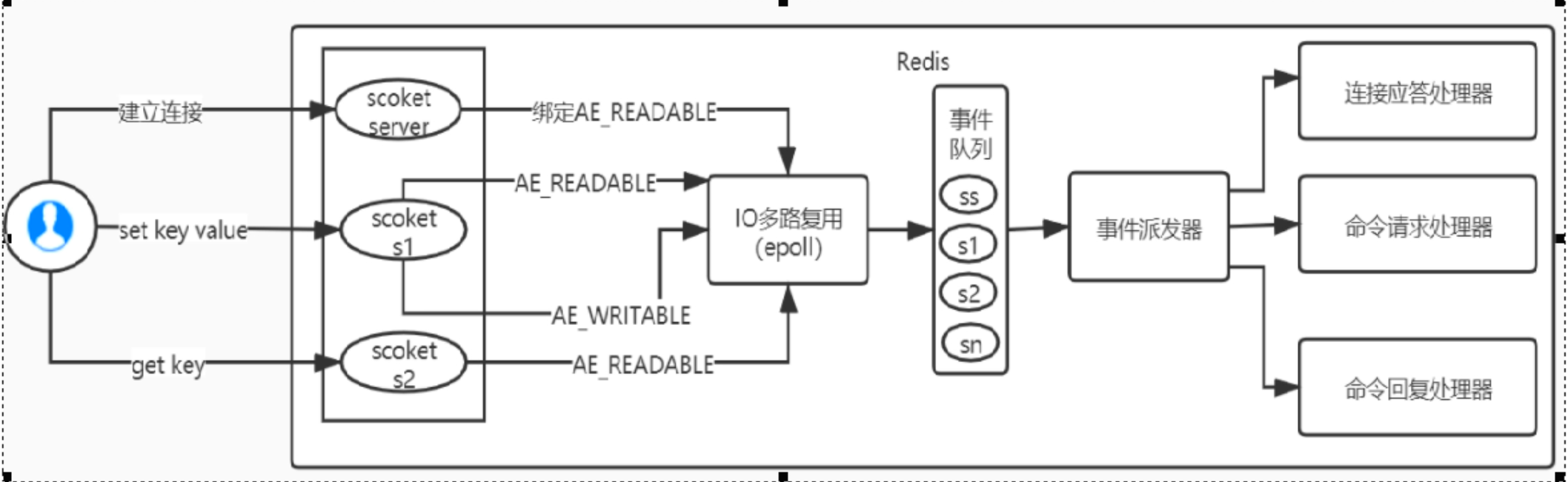
Redis 利用 epoll 来实现 IO 多路复用,将连接信息和事件放到队列里,依次放到文件事件分派器,事件分派器将事件分发给事件处理器
Redis 是跑在单线程中的,所有的操作都是按照顺序线性执行的,但是由于读写操作等待用户输入或输出都是阻塞的,所以 IO 操作在一情况下往往不能直接返回,这会导致某一文件的 I0 阻塞导致整个进程无法对其它客户提供服务,而 IO 多路复用就是为了解决这个问题而
出现,所谓 IO 多路复用机制,就是说通过一种机制,可以监视多个描述符,一旦某个描述符就绪,一般是读就绪或写就绪,能够通知程序进行相应的读写操作,这种机制的使用需要 select、poll、epoll 来配合,多个连接共用一个阻塞对象,应用程序只需要在一个阻塞对象上等待,无需阻塞等待所有连接,当某条连接有新的数据可以处理时,操作系统通知应用程序,线程从阻塞状态返回,开始进行业务理
Redis 服务采用 Reactor 的方式来实现文件事件处理器,每一个网络连接其实都对应一个文件描述符,Redis 基于 Reactor 模式开发了网络事件处理器,这个处理器被称为文件事件处理器,它的组成结构为 4 部分
- 多个套接字
- IO 多路复用程序
- 文件事件分派器
- 事件处理器
因为文件事件分派器队列的消费是单线程的,所以 Redis 才叫单线程模型
IO 模型
BIO
- 当用户进程调用了 recvfrom 这个系统调用,kernel就开始了 IO 的第一个阶段:准备数据,对于网络 IO 来说,很多时候数据在一开始还没有到达,比如,还没有收到一个完整的UDP包,这个时候 kernel 就要等待足够的数据到来,这个过程需要等待,也就是说数据被拷贝到操作系统内核的缓冲区中是需要一个过程的
- 而在用户进程这边,整个进程会被阻塞,当 kernel 一直等到数据淮备好了,它就会将数据从 kernel 中拷贝到用户内存,然后 kernel 返回结果,用户进程才解除 block 的状态,重新运行起来
- 从用户态到内核态,然后再从内核态到用户态都在阻塞
tomcat7 之前使用 BIO 多线程连接问题
NIO
- 在 NIO 模式中,一切都是非阻塞的
- accept 方法是非阻寒的,如果没有客户端连接,就返回 error
- read 方法是非阻塞的,如果 read 方法读取不到数据就返回 error,如果读取到数据时只阻寒 read 方法读数据的时间
- 在 NIO 模式中,只有一个线程,当一个客户端与服务端进行连接,这个 socket 就会加入到一个数组中,隔一段时间遍历一次,看这个 socket 的 read 方法是否能读到数据,这样一个线程就能处理多个容户端的连接和读取了
当用户进程发出 read 操作作时,如果 kernel 中的数据还没有准备好,那么它并不会 block 用户进程,而是立刻返回一个error,从用户进程角度讲,它发起一个read操作后,并不需要等待,而是马上就得到了一个结果
用户进程判断结果是一个 error 时,它就知道数据还没有准备好,于是它可以再次发送 read 操作,如果 kernel 中的数据准备好了,并且又再次收到了用户进程的 system call,那么它马上就将数据拷贝到了用户内存,然后返回,所以,NIO 特点是用户进程需要不断的主动询问内核数据是否准备完毕
在非阻塞式 IO 模型中,应用程序把一个套接口设置为非阻塞,就是告诉内核,当所请求的 IO 操作无法完成时,不要将进程睡眠而是返回
一个“错误”,应用程序基于 IO 操作函数将不断的轮询数据是否己经准备好,如果没有准备好,继续轮询,直到数据准备好为止
NIO 的问题
- 这个模型在客户端少的时候十分好用,但是客户端如果很多,比如有 1 万个客户端进行连接,那么每次循环就要遍历1万个 socket,如果一万个socket中只 有 10 个 socket 有数据,也会遍历一万个 socket,就会做很多无用功,每次遍历遇到 read 返回 -1 时仍然是一次浪费资源的系统调用
- 而且这个通历过程是在用户态进行的,用户态判断 socket 是否有数据还是调用内核的 read 方法实现的,这就涉及到用户态和内核态的切换,每遍历一个就要切换一次,开销很大
优点:不会阻塞在内核的等待数据过程,每次发起的 IO 请求可以立即返回,不用阻塞等待,实时性较好
缺点:轮询将会不断地询问内核,这将占用大量的 CPU 时间,系统资源利用率较低,所以一般 Web 服务器不使用这种 IO 模型
结论:让 Linux 内核搞定上述需求,将一批文件描述符通过一次系统调用传给内核由内核层去遍历,才能真正解决这个问题,IO 多路复用应运而生,将上述工作直接放进 Linux 内核,不再两态转换而是直接从内核获得结果,因为内核是非阻塞的
IO mutiplexing
IO mutiplexing 就是我们说的 select、poll、epoll,有些地方也称这种 IO 方式为 event driven IO 即事件驱动 IO,就是通过一种机制,一个进程可以监视多个描述符,一旦某个描述符就绪,一般是读就绪或者写就绪,能够通知程序进行相应的读写操作,可以基于一个阻塞对象,同时在多个描述符上等待就绪,而不是使用多个线程,每个文件描述符一个线程,每次 new 一个线程,这样可以大大节省系统资源,所以,IO 多路复用的特点是通过一种机制一个进程能同时等待多个文件描述符,而这些文件描述符(套接字描述符)其中的任意一个进入读就绪状态,select 函数就可以返回
多路复用快的原因在于,操作系统提供了这样的系统调用,使得原来的 while 循环里多次系统调用,变成了一次系统调用+内核层遍历这些文件描述符
多个连接共用一个阻塞对象,应用程序只需要在一个阻塞对象上等待,当某条连接有新的数据可以处理时,操作系统通知应用程序,线程从阻塞状态返回,开始进行业务处理
SELECT
执行过程
- select 是一个阻塞函数,当没有数据时,会一直阻塞在 select 那一行
- 当有数据时会将 rset (bitmap) 中对应的位置置为 1
- select 函数返回,不再阻塞
- 遍历文件描述符数组,判断哪个 fd 被置为1了
- 读取数据,然后处理
优点
- select 其实就是把NIO中用户态要遍历的 fd 数组 (每一个 socket 连接) 拷贝到了内核态,让内核态去遍历,因为用户态判断 socket 是否有数据还是调用内核态的,所以拷贝到内核态后,遍历判断的时候就不用一直用户态到內核态频繁切换了
- 从上述过程中可以看出,select 系统调用后,返回了一个置位后的 &rset,这样用户态只需进行很简单的二进制比较,就能很快知道哪些socket 需要 read 数据,有效提高了效率
缺点
- bitmap 最大 1024 位,一个进程最多只能处理1024个客户端
- &rset 不可重用,每次 socket 有数据就有相应的位会被置位
- select 调用需要传入 fd 数组,需要拷贝一份到内核,高并发场景下这样的拷贝消耗的资源是惊人的
- select 并没有通知用户态哪一个 socket 有数据,仍然需要 O(N) 的遍历,select 仅仅返回可读文件描述符的个数,具体哪个可读还是要用户自己遍历
POLL
执行流程
- 将 5 个 fd 从用户态拷贝到内核态
- poll 为阻塞方法,执行 poll 方法,如果有数据会将 fd 对应的 revents 置为 POLLIN
- poll方法返回
- 循环遍历,查找哪个 fd 被置位为 POLLIN
- 将 revents 重置为0便于复用
- 对置位的 fd 进行读取和处理
优点
- poll 使用 pollfd 数组代替 select 中的 bitmap,数组没有 1024 的限制,可以一次管理更多的 client,它和 select 的主要区别就是
去掉了只能监听 1024 个文件描述符的限制 - 当 pollfds 数组中有事件发生,相应的 revents 置位为 1,遍历的时候又置为 0,实现了 pollfd 数组的重用
缺点
- poll 解决了 select 缺点中的前两条,其本质原理还是 select 的方法,还存在select中原来的问题
- pollfds 数组拷贝到了内核态,仍然有开销
- poll 并没有通知用户态哪一个 socket 有数据,仍然需要 O(N) 的遍历
EPOLL
- epoll_create:创建一个 epoll 句柄
- epoll_ctl:向内核添加、修改或者删除要监控的文件描述符
- epoll_wait:类似发起了 select 调用
执行过程
- 当有数据的时候,会把真正的文件描述符置位,但是 epoll 没有 revent 标志位,所以并不是真正的置位,这时候会把数据的文件描述符放到队首,是红黑树的结构
- epoll 会返回有数据的文件描述符的个数
- 根据返回的个数,读取前 N 个文件描述符即可
- 读取、处理
总结
| select | poll | epoll | |
|---|---|---|---|
| 操作方式 | 遍历 | 遍历 | 回调 |
| 数据结构 | bitmap | 数组 | 红黑树 |
| 最大连接数 | 1024/2048,操作系统位数决定 | 无上限 | 无上限 |
| 最大支持文件描述符数 | 有最大值限制 | 65535 | 65535 |
| fd 拷贝 | 每次调用都需要将 fd 集合从用户态拷贝到内核态 | 每次调用都需要将 fd 集合从用户态拷贝到内核态 | 首次调用需要epoll_ctl拷贝,后续使用epoll_wait无需拷贝 |
| 工作效率 | 每次调用都进行线性遍历,时间复杂度为 O(N) | 每次调用都进行线性遍历,时间复杂度为 O(N) | 事件通知方式,每次 fd 就绪,系统注册的回调函数就会被调用,将就绪的 fd 放到就绪列表,时间复杂度为 O(1) |