
MySQL进阶之基础架构
简介
- MySQL 是一个关系型数据库管理系统,由瑞典 MySQL AB公司开发,目前属于 Oracle 公司
- MySQL 是一种关联数据库管理系统,将数据保存在不同的表中,而不是将所有数据放在一个大仓库内,这样就增加了速度并提高了灵活性
- MySQL 是可以定制的,采用了 GPL 协议,你可以修改源码来开发自己的 Mysql 系统
- MySQL 支持大型的数据库。可以处理拥有上千万条记录的大型数据库
- MySQL 使用标准的 SQL 数据语言形式
- MySQL 可以允许于多个系统上,并且支持多种语言。这些编程语言包括 C、C++、Python、Java、Perl、PHP、Eiffel、Ruby 和 Tcl 等
- MySQL 支持大型数据库,支持 5000 万条记录的数据仓库,32 位系统表文件最大可支持 4GB,64 位系统支持最大的表文件为 8TB
安装
下载地址
http://dev.mysql.com/downloads/mysql
预检查是否安装过 MySQL
rpm -qa|grep mysql
卸载老版本 MySQL
rpm -e --nodeps mysql-libs
提升 /tmp文件夹权限
# 由于mysql安装过程中,会通过mysql用户在/tmp目录下新建tmp_db文件,所以请给/tmp较大的权限
chmod -R 777 /tmp
安装
#在mysql的安装文件目录下执行
rpm -ivh MySQL-server-5.5.54-1.linux2.6.x86_64.rpm
rpm -ivh MySQL-client-5.5.54-1.linux2.6.x86_64.rpm
查看安装版本
mysqladmin --version
MySQL 启动
service mysql start
MySQL 停止
service mysql stop
设置自启动
chkconfig --level 2345 mysql on
首次登陆修改密码
/usr/bin/mysqladmin -u root password '123456'
MySQL 安装目录
ps -ef|grep mysql
| 参数 | 路径 | 解释 | 备注 |
|---|---|---|---|
| --basedir | /usr/bin | 相关命令目录 | mysqladmin mysqldump等命令 |
| --datadir | /var/lib/mysql/ | mysql数据库文件的存放路径 | |
| --plugin-dir | /usr/lib64/mysql/plugin | mysql插件存放路径 | |
| --log-error | /var/lib/mysql/jack.atguigu.err | mysql错误日志路径 | |
| --pid-file | /var/lib/mysql/jack.atguigu.pid | 进程pid文件 | |
| --socket | /var/lib/mysql/mysql.sock | 本地连接时用的unix套接字文件 | |
| /usr/share/mysql | 配置文件目录 | mysql脚本及配置文件 | |
| /etc/init.d/mysql | 服务启停相关脚本 |
调整字符集
# 查看字符集
SHOW VARIABLES LIKE 'character%';
修改my.cnf
在 /usr/share/mysql/ 中找到 my.cnf 的配置文件,拷贝其中的my-huge.cnf 到 /etc/ 并命名为 my.cnf
[client]
default-character-set=utf8mb4
[mysqld]
character_set_server=utf8mb4
character_set_client=utf8mb4
collation-server=utf8_general_ci
[mysql]
default-character-set=utf8mb4
修改数据库的字符集
ALTER DATABASE 库名 CHARACTER SET 'utf8';
修改数据表的字符集
ALTER TABLE 表名 CONVERT TO CHARACTER SET 'utf8';
配置文件
二进制日志 log-bin
- 主要用作主从复制和备份恢复
错误日志 log-error
- 默认是关闭的,记录严重的警告和错误信息,每次启动和关闭的详细信息等
慢查询日志 log
- 默认关闭,记录查询的sql语句,如果开启会减低mysql的整体性能,因为记录日志也是需要消耗系统资源的
- 可自定义“慢”的概念:0-10秒之间的一个数,慢查询日志会将超过这个查询事件的查询记录下来,方便找到需要优化的 sql
数据文件
MyISAM 存放方式
| 文件类型 | 作用 |
|---|---|
| frm文件(framework) | 存放表结构 |
| myd文件(data) | 存放表数据 |
| myi文件(index) | 存放表索引 |
InnoDB 存放方式
| 文件类型 | 作用 |
|---|---|
| ibdata1 | Innodb引擎将所有表的的数据都存在这里面 /usr/share/mysql/ibdata1,而frm文件存放在库同名的包下 |
| frm文件 | 存放表结构 |
| myi文件(index) | set innodb_file_per_table=on,设在为 on 后 单独以 table名.ibd 的文件名存储 |
用户管理
创建用户
CREATE USER zhang3 IDENTIFIED BY '密码';
查看用户
select host,user,password,select_priv,insert_priv,drop_priv from mysql.user;
host 连接类型
- % 表示所有远程通过 TCP方式的连接
- IP 地址如 (192.168.1.2,127.0.0.1) 通过指定 IP 地址进行的 TCP 方式的连接
- 机器名,通过制定i网络中的机器名进行的TCP方式的连接
::1,IPv6的本地ip地址,等同于IPv4的 127.0.0.1- localhost,本地方式通过命令行方式的连接 ,比如
mysql -u xxx -p 123xxx方式的连接。
user 用户名
- 同一用户通过不同方式链接的权限是不一样的
password 密码
- 所有密码串通过 password (明文字符串) 生成的密文字符串。加密算法为 MYSQLSHA1 ,不可逆
- mysql 5.7 的密码保存到 authentication_string 字段中,不再使用 password 字段。
修改当前用户密码
SET PASSWORD = PASSWORD ( '123456' )
修改某个用户的密码
UPDATE mysql.USER
SET PASSWORD = PASSWORD ( '123456' )
WHERE
USER = 'zhouju';
修改用户名
UPDATE mysql.USER
SET USER = 'li4'
WHERE
USER = 'wang5';
注意:所有通过 user 表的修改,必须 使用
flush privileges命令才能生效
删除用户
DROP USER 用户名;
不要通过 DELETE FROM USER u WHERE USER = '用户名' 进行删除,系统会有残留信息保留
权限管理
授予权限
# 该命令如果发现没有该用户,则会直接新建一个用户
GRANT 权限1,权限2,…权限n ON 数据库名.表名 TO 用户名@用户地址 IDENTIFIED BY '密码';
# 给li4用户授予数据库下的所有表的插删改查的权限
GRANT SELECT,INSERT,DELETE,DROP ON 数据库名.* TO li4 @localhost;
# 授予通过网络方式登录的的joe用户 ,对所有库所有表的全部权限,密码设为123.
GRANT ALL PRIVILEGES ON *.* TO joe @'%' IDENTIFIED BY '123';
注意:
- 就算 all privileges 了所有权限,grant_priv 权限也只有 root 才能拥有
- 给 root 赋连接口令 grant all privileges on . to root@'%' ;后新建的连接没有密码,需要设置密码才能远程连接:
update user set password=password('root') where user='root' and host='%';
收回权限
REVOKE 权限1,权限2,…权限 n ON 数据库名称.表名称 FROM 用户名@用户地址;
# 收回用户 joe 全库全表的所有权限
REVOKE ALL PRIVILEGES ON mysql.* FROM joe@localhost;
# 收回用户 joe mysql 库下的所有表的插删改查权限
REVOKE ALL PRIVILEGES ON mysql.* FROM joe@localhost;
用户重新登录后生效或者调用:flush privileges
查看权限
# 查看当前用户权限
SHOW GRANTS;
配置
大小写
# 查看大小写设置
SHOW VARIABLES LIKE '%lower_case_table_names%'
-
windows 系统默认大小写不敏感
-
Linux 系统默认为 0,大小写敏感
-
设置 1,大小写不敏感,创建的表,数据库都是以小写形式存放在磁盘上,对于 sql 语句都是转换为小写对表和 DB 进行查找
-
设置 2,创建的表和 DB 依据语句上格式存放,凡是查找都是转换为小写进行
-
当想设置为大小写不敏感时,要在 my.cnf 这个配置文件 [mysqld] 中加入
lower_case_table_names = 1,然后重启服务器 -
需要在重启数据库实例之前就需要将原来的数据库和表转换为小写,否则更改后将找不到数据库名
-
sql_mode
ONLY_FULL_GROUP_BY
对于 GROUP BY 聚合操作,如果在 SELECT 中的列,没有在 GROUP BY 中出现,那么这个SQL是不合法的,因为列不在 GROUP BY 从句中
NO_AUTO_VALUE_ON_ZERO
该值影响自增长列的插入,默认设置下,插入 0 或 NULL 代表生成下一个自增长值。如果用户希望插入的值为 0,而该列又是自增长的,那么这个选项就有用了
STRICT_TRANS_TABLES
在该模式下,如果一个值不能插入到一个事务表中,则中断当前的操作,对非事务表不做限制
NO_ZERO_IN_DATE
在严格模式下,不允许日期和月份为零
NO_ZERO_DATE
设置该值,mysql数据库不允许插入零日期,插入零日期会抛出错误而不是警告
ERROR_FOR_DIVISION_BY_ZERO
在 INSERT 或 UPDATE 过程中,如果数据被清除,则产生错误而非警告,如果未给出该模式,那么数据被清除时 MySQL 返回 NULL
NO_AUTO_CREATE_USER
禁止 GRANT 创建密码为空的用户
NO_ENGINE_SUBSTITUTION
如果需要的存储引擎被禁用或未编译,那么抛出错误,不设置此值时,用默认的存储引擎替代,并抛出一个异常
PIPES_AS_CONCAT
将"||"视为字符串的连接操作符而非或运算符,这和 Oracle 数据库是一样的,也和字符串的拼接函数 Concat 相类似
ANSI_QUOTES
启用 ANSI_QUOTES 后,不能用双引号来引用字符串,因为它被解释为识别符
查看 sql_mode
SELECT @@GLOBAL.sql_mode
设置 sql_mode
SET sql_mode = ONLY_FULL_GROUP_BY
# 设置多个
SET sql_mode = 'ONLY_FULL_GROUP_BY,NO_AUTO_VALUE_ON_ZERO';
MySQL 逻辑架构
和其它数据库相比,MySQL有点与众不同,它的架构可以在多种不同场景中应用并发挥良好作用。主要体现在存储引擎的架构上,插件式的存储引擎架构将查询处理和其它的系统任务以及数据的存储提取相分离。这种架构可以根据业务的需求和实际需要选择合适的存储引擎
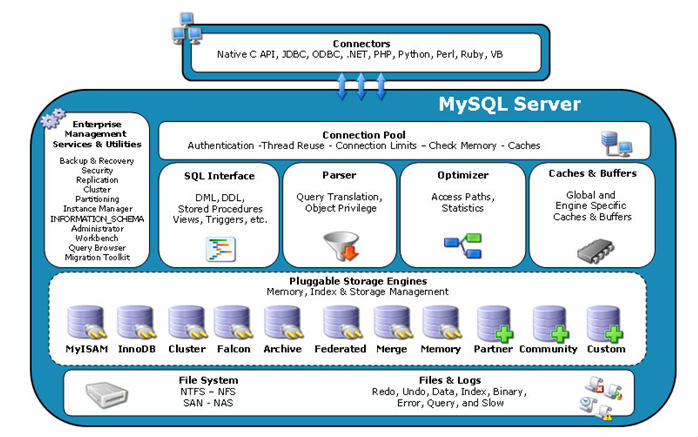
连接层
最上层是一些客户端和连接服务,包含本地sock通信和大多数基于客户端/服务端工具实现的类似于tcp/ip的通信,主要完成一些类似于连接处理、授权认证、及相关的安全方案,在该层上引入了线程池的概念,为通过认证安全接入的客户端提供线程,同样在该层上可以实现基于SSL的安全链接,服务器也会为安全接入的每个客户端验证它所具有的操作权限
服务层
- Management Serveices & Utilities:系统管理和控制工具
- SQL Interface:SQL接口接受用户的 SQL 命令,并且返回用户需要查询的结果,比如 select from 就是调用 SQL Interface
- Parser:解析器,SQL 命令传递到解析器的时候会被解析器验证和解析
- Optimizer:查询优化器,SQL 语句在查询之前会使用查询优化器对查询进行优化。
- Cache 和 Buffer:查询缓存,如果查询缓存有命中的查询结果,查询语句就可以直接去查询缓存中取数据,这个缓存机制是由一系列小缓存组成的。比如表缓存,记录缓存,key缓存,权限缓存等, 缓存是负责读,缓冲负责写
引擎层
存储引擎层,存储引擎真正的负责了 MySQL 中数据的存储和提取,服务器通过 API 与存储引擎进行通信,不同的存储引擎具有的功能不同,这样我们可以根据自己的实际需要进行选取
存储层
数据存储层,主要是将数据存储在运行于裸设备的文件系统之上,并完成与存储引擎的交互
查询流程
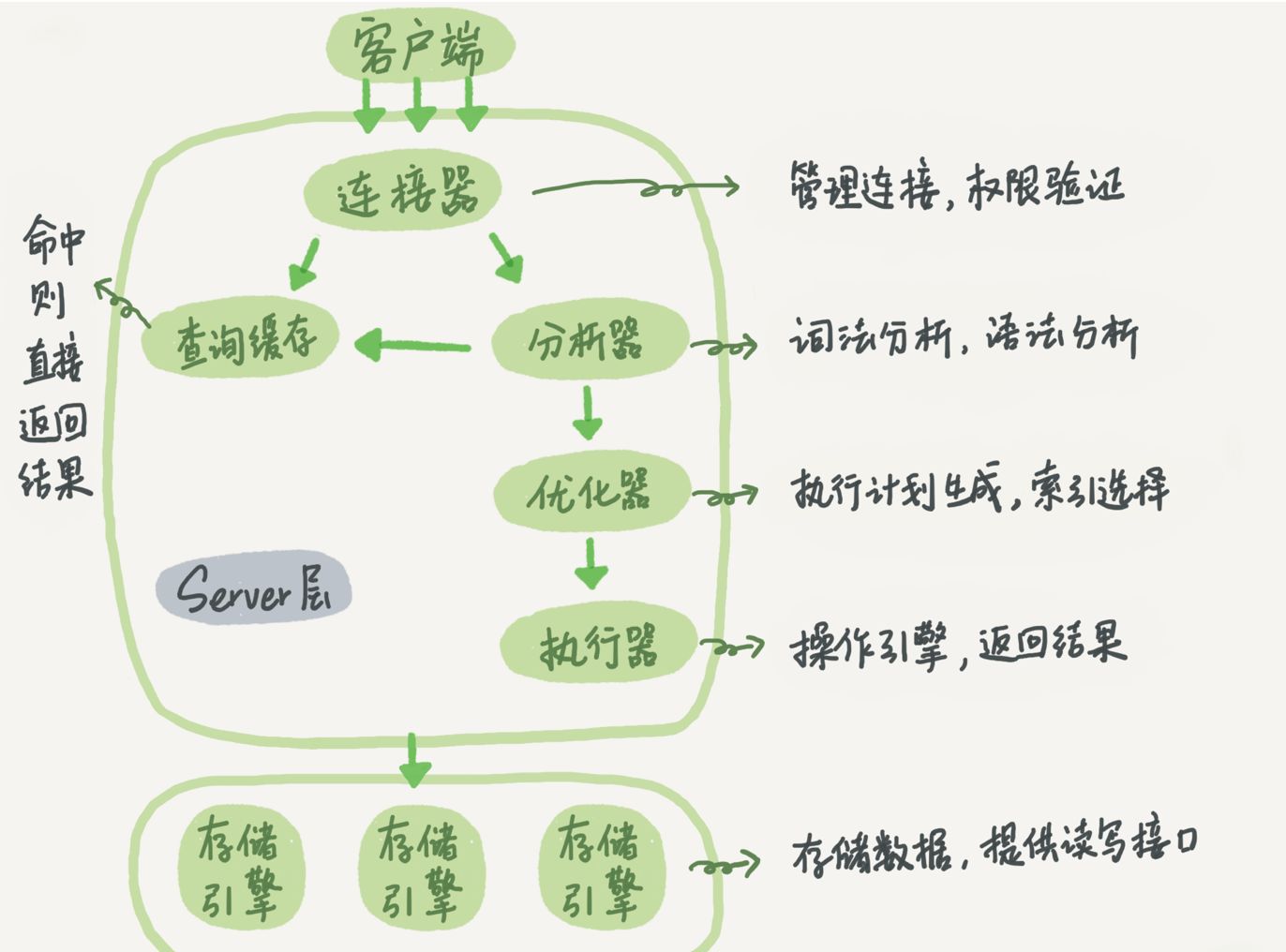
如上图所示:
- MySQL 客户端通过协议与 MySQL 服务器建连接,发送查询语句,先检查查询缓存,如果命中(一模一样的 sql 才能命中),直接返回结果,否则进行语句解析,也就是说,在解析查询之前,服务器会先访问查询缓存 (query cache) —— 它存储 SELECT 语句以及相应的查询结果集,如果某个查询结果已经位于缓存中,服务器就不会再对查询进行解析、优化、以及执行。它仅仅将缓存中的结果返回给用户即可,这将大大提高系统的性能
- 语法解析器和预处理:首先 MySQL 通过关键字将 SQL 语句进行解析,并生成一颗对应的 “解析树”,MySQL 解析器将使用 MySQL 语法规则验证和解析查询,预处理器则根据一些 MySQL 规则进一步检查解析数是否合法
- 查询优化器当解析树被认为是合法的了,并且由优化器将其转化成执行计划,一条查询可以有很多种执行方式,最后都返回相同的结果,优化器的作用就是找到这其中最好的执行计划
- 然后,MySQL默认使用的 BTREE 索引,并且一个大致方向是:无论怎么折腾 sql,至少在目前来说,MySQL最多只用到表中的一个索引
MySQL 存储引擎
查看默认引擎
SHOW VARIABLES LIKE '%storage_engine%';
InnoDB 存储引擎
- InnoDB是 MySQL 的默认事务型引擎,它被设计用来处理大量的短期 (short-lived) 事务,除非有非常特别的原因需要使用其他的存储引擎,否则应该优先考虑InnoDB 引擎-
- InnoDB 支持行级锁,适合高并发情况
MyISAM 存储引擎
- MyISAM 提供了大量的特性,包括全文索引、压缩、空间函数 (GIS) 等,但 MyISAM 不支持事务和行级锁 (myisam改表时会将整个表全锁住)
- 缺陷是崩溃后无法安全恢复
Archive引擎
- Archive存储引擎只支持 INSERT 和 SELECT 操作,在MySQL5.1之前不支持索引,Archive表适合日志和数据采集类应用
- 适合低访问量大数据等情况,根据英文的测试结论来看,Archive 表比 MyISAM 表要小大约75%,比支持事务处理的InnoDB表小大约83%
Blackhole引擎
Blackhole引擎没有实现任何存储机制,它会丢弃所有插入的数据,不做任何保存,但服务器会记录 Blackhole 表的日志,所以可以用于复制数据到备库,或者简单地记录到日志,但这种应用方式会碰到很多问题,因此并不推荐。
CSV引擎
- CSV引擎可以将普通的CSV文件作为MySQL的表来处理,但不支持索引
- CSV引擎可以作为一种数据交换的机制,非常有用
- CSV存储的数据直接可以在操作系统里,用文本编辑器,或者excel读取
Memory引擎
-
如果需要快速地访问数据,并且这些数据不会被修改,重启以后丢失也没有关系,那么使用Memory表是非常有用
-
Memory表至少比MyISAM表要快一个数量级(使用专业的内存数据库更快,如redis)
Federated引擎
Federated引擎是访问其他MySQL服务器的一个代理,尽管该引擎看起来提供了一种很好的跨服务器的灵活性,但也经常带来问题,因此默认是禁用的
MyISAM 和 InnoDB 对比
| 对比项 | MyISAM | InnoDB |
|---|---|---|
| 主外键 | 不支持 | 支持 |
| 事务 | 不支持 | 支持 |
| 行表锁 | 只支持表锁,,即使操作一条记录也会锁住整个表,不适合高并发的操作 | 行锁,操作时只锁某一行,不对其它行有影响,适合高并发的操作 |
| 缓存 | 只缓存索引,不缓存真实数据 | 不仅缓存索引还要缓存真实数据,对内存要求较高,而且内存大小对性能有决定性的影响 |
| 表空间 | 小 | 大 |
| 关注点 | 性能 | 事务 |
| 默认安装 | 是 | 是 |
| 默认使用 | 否 | 是 |
| 系统表使用 | 是 | 否 |
-
Innodb 索引 使用 B+TREE MyISAM 索引使用 B-Tree
-
Innodb 主键为聚簇索引,基于聚簇索引的增删改查效率非常高
-
Percona 为 MySQL 数据库服务器进行了改进,在功能和性能上较 MySQL 有着很显著的提升,该版本提升了在高负载情况下的 InnoDB 的性能、为 DBA 提供一些非常有用的性能诊断工具,另外有更多的参数和命令来控制服务器行为
-
该公司新建了一款存储引擎叫 xtradb 完全可以替代 Innodb,并且在性能和并发上做得更好
-
阿里巴巴大部分 mysql 数据库其实使用的 percona 的原型加以修改